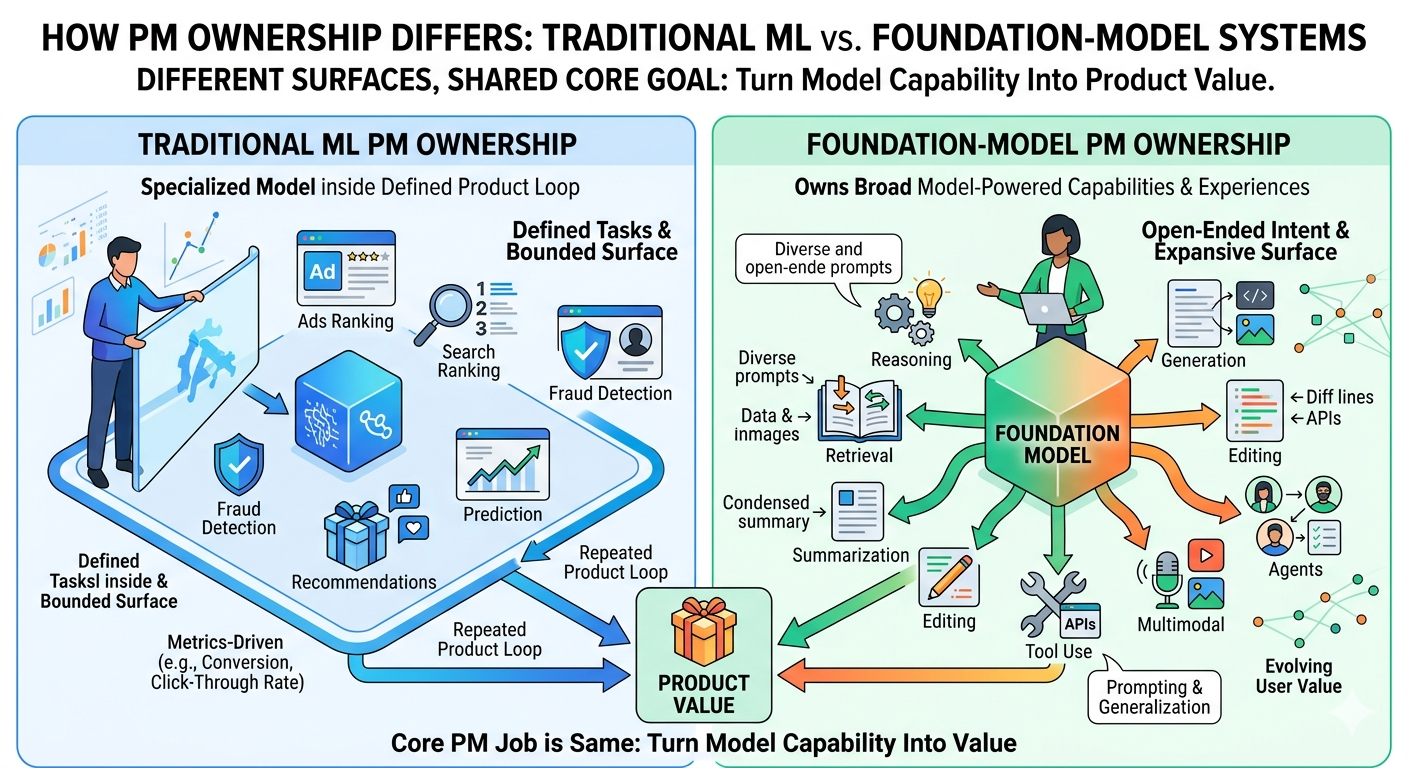
As a follow-up to A Strong Model Is Not the Same as a Strong Product, this piece looks at a related but different question: how PM ownership differs across traditional ML systems and foundation-model systems.
These are often different PM roles. An ads ranking PM, search ranking PM, fraud PM, or recommendations PM is not necessarily doing the same job as a foundation-model PM. Both are AI product roles, but the ownership surface is different.
The core PM job is the same: turn model capability into product value. But the product judgment required is different.
Traditional ML PMs usually own a specialized model system inside a defined product loop: ranking, classification, detection, prediction, recommendation, fraud, search, or ads.
Foundation-model PMs usually own a broader model-powered capability or experience: reasoning, generation, retrieval, summarization, editing, tool use, agents, multimodal understanding, or model behavior across open-ended user intent.
| Area | Product owns in traditional ML systems | Product owns in foundation-model systems |
|---|---|---|
| Problem and use case | Define the user problem, why it matters, and which use cases matter most. The task is usually bounded: rank, classify, detect, predict, recommend. | Define the broader behavior or generation envelope: what the model should answer, retrieve, generate, edit, refuse, ask, or do across open-ended user intent. |
| Inputs and context | Define the input signals the model should use: user actions, metadata, labels, images, text fields, historical behavior, ranking signals, transaction data, or other features. | Since the base model has already been pre-trained, PM is less focused on defining every feature from scratch and more focused on defining the runtime context: prompts, retrieved docs, files, tools, memory, permissions, product state, reference assets, and constraints. |
| Model selection | Define what "best" means for the product: quality, latency, cost, safety, privacy, reliability, robustness, and user value. Research/ML owns the technical model choice. | Define what "best" means across a broader surface: reasoning quality, groundedness, context length, controllability, multimodal quality, tool use, safety behavior, inference cost, and whether the model should be used directly, fine-tuned, routed, distilled, or grounded with retrieval. |
| Tradeoffs | Make product tradeoffs: accuracy vs latency, precision vs recall, quality vs cost, automation vs human review, personalization vs privacy. | Make broader system tradeoffs: model vs retrieval, model vs tools, model vs deterministic rules, autonomy vs approval, creativity vs control, memory vs privacy, reasoning depth vs latency. |
| Golden dataset | Ensure the dataset reflects real users, priority scenarios, edge cases, and the launch bar — not just convenient examples. | Ensure the eval set reflects real prompts, ambiguous asks, multi-turn flows, adversarial cases, tool-use cases, multimodal examples, and failure scenarios. |
| Evals | Define what "good enough" means. Model quality may include accuracy, precision, recall, ranking lift, calibration, robustness, latency, cost, and reliability. | Define broader e-KPIs: correctness, groundedness, helpfulness, reasoning quality, instruction following, refusal quality, tool-use accuracy, controllability, safety, latency, and cost. |
| Failure modes | Define which failures are acceptable and which are launch-blocking: wrong prediction, bad ranking, false positive, false negative, model drift, poor calibration. | Define open-ended failure modes: hallucinations, fabricated citations, wrong tool calls, privacy leaks, bad refusals, prompt injection, unsafe output, visual artifacts, or identity drift. |
| Product integration | Decide how the model fits into the product workflow: ranking, scoring, labeling, alerting, recommending, detecting. | Decide where the foundation model sits in the system: before search, after retrieval, inside an agent loop, behind an editor, connected to tools, grounded with RAG, or gated by human approval. |
| Success criteria | Own user impact, business impact, adoption, trust, safety, reliability, and cost — and connect those outcomes to model-quality metrics. | Own the same top-level success criteria, but prove them across a broader surface: more inputs, contexts, behaviors, modalities, tools, and failure modes. |
| Launch readiness | Own UX, safety, evals, monitoring, rollout, rollback, comms, support, and GTM. This includes monitoring for model drift, task performance, business metrics, latency, cost, reliability, and guardrails. | Own launch readiness across model behavior: prompt evals, red-teaming, grounding checks, refusal testing, tool-permission testing, and monitoring for hallucinations, refusals, tool calls, safety regressions, prompt patterns, and quality across contexts. |